Web Crawler阅读笔记
Posted on 日 09 八月 2015 in Reading • Tagged with python, Crawler
看了下爬虫是怎么设计的,虽然材料有点老旧,但可以学到许多基础知识,WebCrawler
1 Overview
爬虫的目的:快速高效地收集尽可能多的有用的网页。
必须满足的特性:鲁棒性(Robustness),可能会遇到一些页面误导爬虫陷入无限循环中(honeypot);礼节性(Politeness),遵守一些隐含的或者明确的策略调整访问页面的速率(如robots协议)。
应该满足的特性:分布式地(Distributed),可伸缩(Scalable),高效的(Performance and efficiency),保持最新(Freshness),功能易于扩展(Extensible)
2 Crawling
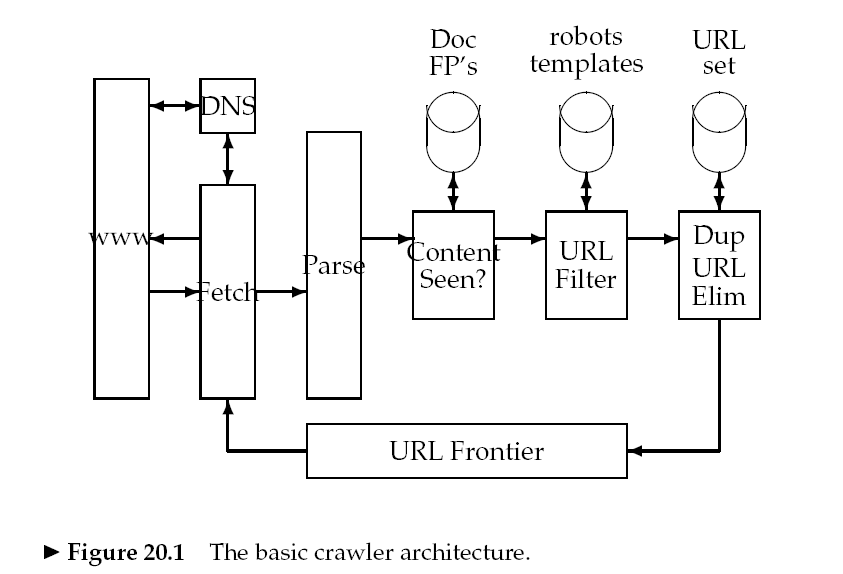
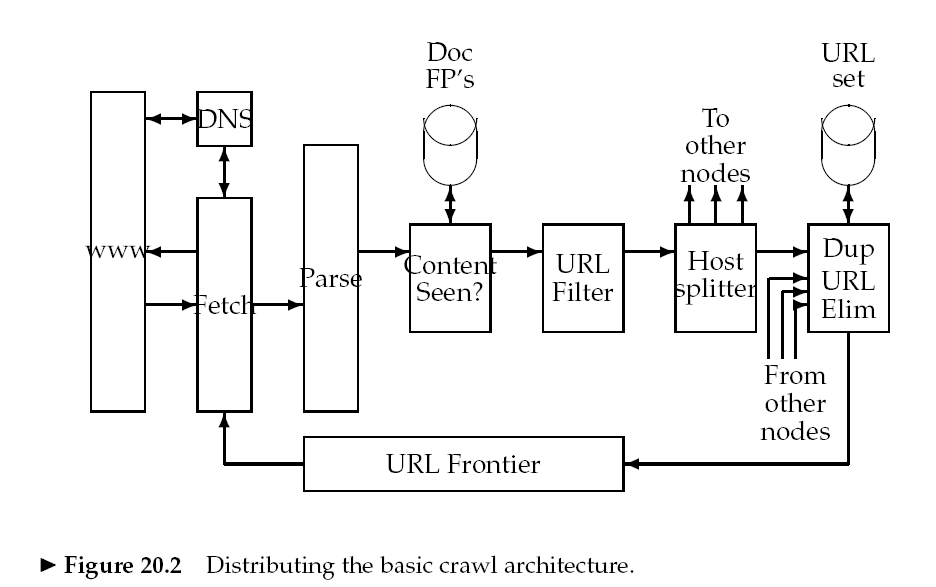
爬虫从一些种子集(seed set)URL开始爬取内容,将爬取的内容进行解析,抽取出文本放入文本索引器,抽取出url放入URL frontier。之后爬虫从url frontier获取一个url,继续爬取。
2.1 Architecture