Web Crawler阅读笔记
Posted on 日 09 八月 2015 in Reading
看了下爬虫是怎么设计的,虽然材料有点老旧,但可以学到许多基础知识,WebCrawler
1 Overview
爬虫的目的:快速高效地收集尽可能多的有用的网页。
必须满足的特性:鲁棒性(Robustness),可能会遇到一些页面误导爬虫陷入无限循环中(honeypot);礼节性(Politeness),遵守一些隐含的或者明确的策略调整访问页面的速率(如robots协议)。
应该满足的特性:分布式地(Distributed),可伸缩(Scalable),高效的(Performance and efficiency),保持最新(Freshness),功能易于扩展(Extensible)
2 Crawling
爬虫从一些种子集(seed set)URL开始爬取内容,将爬取的内容进行解析,抽取出文本放入文本索引器,抽取出url放入URL frontier。之后爬虫从url frontier获取一个url,继续爬取。
2.1 Architecture
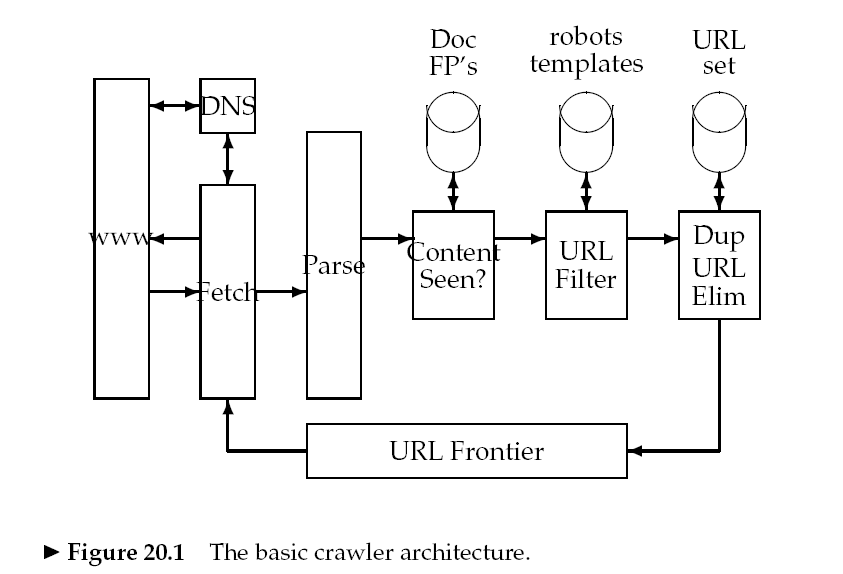
2.2 DNS resolution
DNS解析是一个瓶颈。
解决方法:缓存 -> 标准库中的实现通常是同步的,一个请求得等到之前请求完成了才开始执行 -> 实现一个异步版本
2.3 URL frontier
(1)两个重要的考虑:高质量且更新频繁的页面需要优先作为频繁爬取的对象;关于礼节性,需避免在很短的时间间隔内重复爬取一个host。
(2)frontier分成两部分:
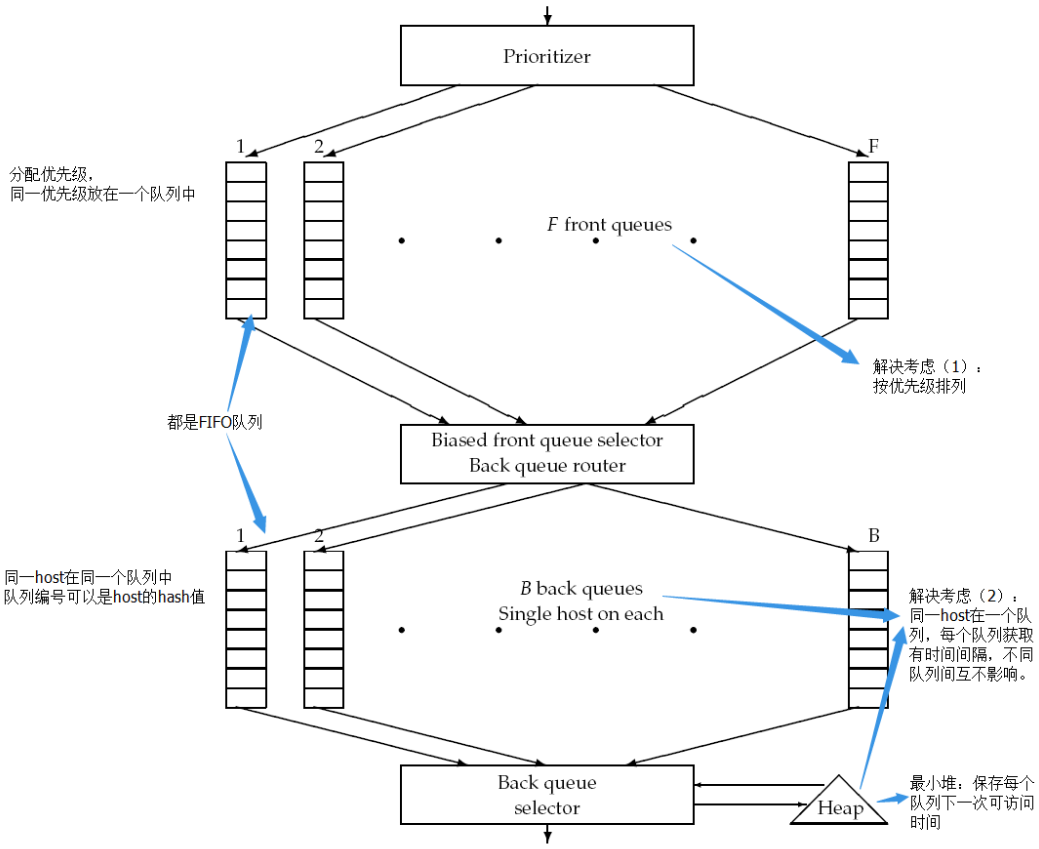
(3)过程:crawler从heap中获取一个队列的可访问时间,等到该时间时,获取该队列(设为j)的头URL(设为u),获取u的内容。结束后,判断这个队列是否为空。若空,则从front queue中获取URL(设为v)来填充它。对于选择哪个front queue,是按照优先级获取的(如一个随机获取的方案,按照优先级的高低,选中的概率不同),保持优先级高的更快流向back queue。先判断back queue是否已经有v的队列,有则放入该队列,并且继续到front queues中获取下一个,直到队列j不空为止。然后更新j的时间,放入heap中。
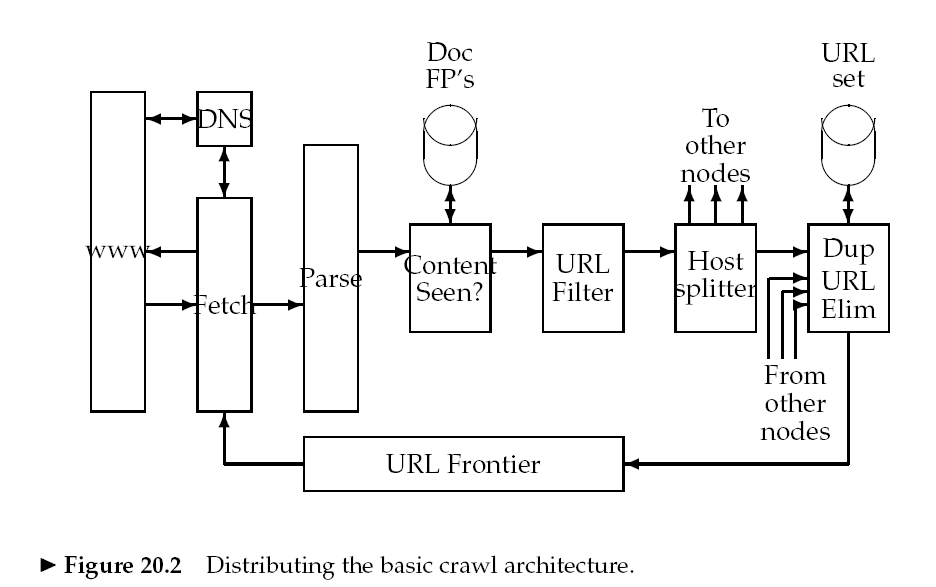
3 Distributing indexes
两种方式:(1)根据术语(关键字?)分割,即全局索引组织。(2)根据文档分割,即本地索引组织。
前者,将术语划分为各自独立的子集,每个子集存于一个节点。当查询时,把请求发给所有包含查询关键字的节点即可,最后将结果取交集。
后者,将文档划分为子集,每个节点存储一个子集。当查询时,需将请求发往所有节点,最后将结果取并集。
4 Connectivity servers
建图 -> 邻接表 -> 某一行可以由它之前的7行中的一行变换得到或者直接从空行产生,用一个3bits表示选择了哪一行,然后标记元素状态(修改,删除或添加) -> 选择由哪一行得到,需由一个启发函数判断两者的相似度,如果超过阈值则判断为相似,可以由这一行得到 -> 相似度阈值太高,则会导致许多需重新生成的行,太低则会导致恢复一行的数据需要使用到太多的间接行。